
初入PWN
前提工具配置:
(1)Linux系统虚拟机:配置python3 、安装pwntools的pwn模块、安装gdb、安装pip(其他的工具在做题遇到时再去安装)
(2)本机IDA pro静态调试器和Ollydbg动态调式器(两个都要有32bit以及64bit的版本)
语法要求:
(1)汇编语法
(2)c语言(c++最好也掌握,不过这比较少见)
(3)python
(4)java(后面的补充学习,新手没必要学)
工具使用要求:
(1)学会IDA的静态调试
(2)学会gdb的动态调试
(3)pwntools的使用
·······
一、PWN模块中用到的函数
| 函数 | 用途 |
|---|---|
| send(data) | 发送数据(字符串形式发送) |
| sendline(data) | 发送一行数据,默认在行尾加 \n(字符串形式发送) |
| recv(numb=1096,timeout=default) | 接收指定字节数的数据 |
| buf = p.recvuntil(“\n”, drop=True) | 直到接收到\n为止,drop=True表示丢弃括号里的内容,buf为接收到的输出但不包括丢弃的\n |
| recvrepeat(timeout=default) | 接收数据直到 EOF 或 timeout |
| recvall() | 接收数据直到 EOF |
| recvline(keepends=True) | 接收一行,可选择是否保留行尾的 \n |
| listen(端口) | 开启一个本地的监听端口 |
| remote(‘IP地址’, 端口) | 与目标IP建立一个套接字管道与之远程交互(在线的) |
| interactive() | 可同时读写管道,相当于回到 shell 模式进行交互,在取得 shell 之后调用 |
| p8() p16() p32() p64() | 把括号内数据打包成8位/16位/32位/64位的二进制数 |
| u8() u16() u32() u64() | 把括号内字符串解包成二进制数 |
| process(‘文件路径’),p = process(argv=[‘./vuln’, payload]) | 与本地文件建立一个交互通道,可传递参数 |
| sendlineafter(“string”,payload) | 接收到string后发送payload |
| close() | 关闭交互的通道 |
| ELF(‘文件路径’) | 获取文件对象或者libc库对象 |
| plt[‘函数名’] | 获取函数在PLT表中的地址 |
| got[‘函数名’] | 获取函数在GOT表中的地址 |
| symbols[‘函数名’] 或sym[‘函数名’] |
获取函数plt地址,用在libc里面就是获取libc里的偏移地址 |
| asm(“汇编指令”) | 把汇编指令转换成对应的机器码,机器码是以字符串形式返回 |
| bss(offset) | 返回 .bss 段加上 offset 后的地址 |
| asm(shellcraft.amd64.linux.sh(),arch=’amd64’)(这里是指明x64环境,如果已经有context设置环境就直接写为asm(shellcraft.sh())) | 生成shellcode,一般与asm进行联用,转为对应机器码 |
| context(arch=’amd64’或‘i386’,os=’linux’,log_level=’debug’) | 设置环境 |
| gdb.attach(p,’b* main’) | 调动gdb进行脚本调式 |
| shutdown(‘in’) | 参数为in/read/recv时关闭输出流,参数为out/write/send关闭输入流 |
栈溢出
一、x86架构下的栈溢出
栈区:简单来说就是c语言中创建的局部变量(例如函数花括号里的变量)的存储位置。内存中的栈区指的是系统栈,由系统自动维护。
栈在程序加载进内存后就会出现
入栈:每个函数都有一个属于自己的栈帧空间,最先压入栈内的是函数的返回地址(用来返回到下一条指令),之后是函数的基地址、参数入栈。例如主调函数在调用函数a时,主调函数先存入自身栈帧的为返回地址、自身基地址、传入函数a的实参(如果有的话),然后替函数a创建一个新栈帧,在新栈帧中先压入函数a的返回地址(为了函数调用结束时,可以返回到下一条指令继续程序),再压入主调函数的基地址(函数调用结束时,返回到主调函数的基地址)以及函数a中的局部变量。此时是高地址往低地址生长(主调函数在的位置为高地址)
退栈:而函数调用结束,则与调用时相反,先从被调函数的局部变量开始直接弹出栈,栈顶指向存储着被调函数基地址(存储主调函数基地址),被调函数基地址被弹出后,释放出主调函数的基地址给ebp,然后将返回地址弹出交给eip去执行,之后便返回到下一条指令的地址(这里举例为主调函数直接调用一个函数,如果层层嵌套,则先会返回到上一个主调函数的栈帧),继续程序的运行,ebp指向此刻的主调函数的基地址
系统中当前正在运行的函数总是在栈顶
与函数状态相关的主要寄存器:esp,ebp,eip:
(1)esp:栈指针寄存器,存放一个指针,该指针永远指向系统栈正在运行的栈帧的栈顶(存储函数调用栈的栈顶地址),在压栈和退栈时发生变化
(2)ebp:基地址指针寄存器,该指针永远指向系统栈正在运行的栈帧的底部,在函数运行时不变,可以用来索引确定函数参数或局部变量的位置
(3)在esp和ebp之间的内存空间为当前栈帧
(4)eip:用来存储即将执行的程序指令的地址,cpu 依照 eip 的存储内容读取指令并执行,eip 随之指向相邻的下一条指令
因此,所谓的栈溢出漏洞,就是利用一些危险函数进行读取远超一个变量所需的数值,覆盖到相邻栈中的数值,从而修改相邻栈中的变量的值,往这些修改的值中注入我们所需要的跳转的例如shellcode,函数地址等,使程序崩坏或是让程序执行一些我们想要执行的程序,达到破坏的目的
x86下的CPU包含的8个四字节的通用寄存器:

寄存器使用约定:寄存器eax、edx和ecx为主调函数保存寄存器(caller-saved registers),当函数调用时,若主调函数希望保持这些寄存器的值,则必须在调用前显式地将其保存在栈中;被调函数可以覆盖这些寄存器,而不会破坏主调函数所需的数据。寄存器ebx、esi和edi为被调函数保存寄存器(callee-saved registers),即被调函数在覆盖这些寄存器的值时,必须先将寄存器原值压入栈中保存起来,并在函数返回前从栈中恢复其原值,因为主调函数可能也在使用这些寄存器。此外,被调函数必须保持寄存器ebp和esp,并在函数返回后将其恢复到调用前的值,亦即必须恢复主调函数的栈帧。
return to libc
——构造system(“/bin/sh“)
使用前提:ASLR被关闭,内存中存在可达到目的的特定函数
system地址:在ASLR 被关闭的前提下,我们可以通过调试工具在运行程序过程中直接查看 system() 的地址,也可以查看动态库在内存的起始地址,再在动态链接库内查看函数的相对偏移位置,通过计算得到函数的绝对地址。
/bin/sh字符串地址:可以在动态库里搜索这个字符串,如果存在,就可以按照动态库起始地址+相对偏移来确定其绝对地址。如果在动态库里找不到,可以将这个字符串加到环境变量里,再通过getenv() 等函数来确定地址。
ROP ( Return Oriented Programming )
——修改返回地址,让其指向内存中已有的一段指令
利用一个及以上的gadget执行指令,最终调用能修改权限的函数,例如编号为125的函数mprotect()可修改栈的属性,从而利用shellcode。若是要连续使用多个gadget时一定要找含有ret指令的片段
被调用函数的编号应存入 eax,调用参数应按顺序存入 ebx,ecx,edx,esi,edi 中
那么如果要调用函数,就需要参数,而参数被存入在上方列举的寄存器中,那么此时我们要做的就是向寄存器存入我们需要的参数 :
1)如果在内存中已经存在我们要的数据,可用mov指令来存入
2)用pop指令来将栈顶数据弹入寄存器,pop 所传输的数据应该在 gadget 地址之后,如图:
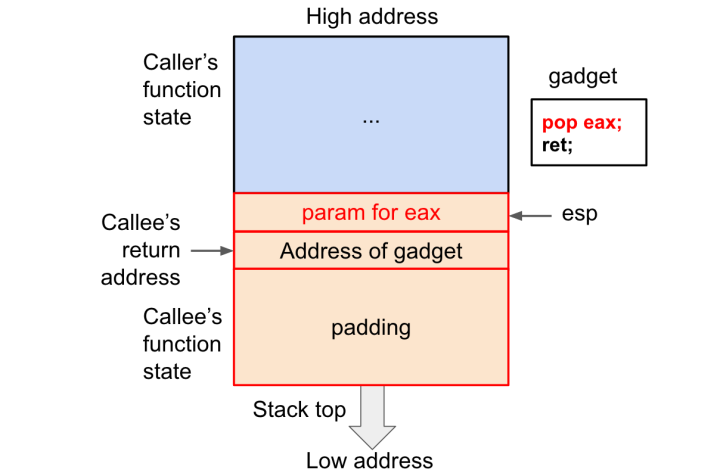
我们可以使用 push esp 这个gadget来执行shellcode
对于所有包含 pop 指令的 gadget,在其gadget地址之后都要添加 需要pop传入寄存器的数据,同时在所有 gadget 最后包含一段shellcode
如果利用 gadget 读取 ebp 的值再加上某个合适的数值,就可以保证溢出数据都具有可执行权限,这样就不再需要获取确切地址,也就具有了绕过内存随机化(ALSR)的可能。
Hijack GOT
——修改某个被调用函数的地址,让其指向另外一个函数
该方法是直接把函数修改成我们需要的函数,不再执行原来的函数,而不是上方执行某个函数后由返回地址进行跳转
函数在链接库中定位所用到的外部函数会用到GOT和PLT这两张表。GOT 全称是全局偏移量表(Global Offset Table),用来存储外部函数在内存的确切地址。GOT 存储在数据段(Data Segment)内,可以在程序运行中被修改。PLT 全称是程序链接表(Procedure Linkage Table),用来存储外部函数的入口点(entry),换言之程序总会到 PLT 这里寻找外部函数的地址。PLT 存储在代码段(Code Segment)内,在运行之前就已经确定并且不会被修改,所以 PLT 并不会知道程序运行时动态链接库被加载的确切位置。那么 PLT 表内存储的入口点是 GOT 表中对应条目的地址。
程序需要调用某个外部函数时,首先到 PLT 表内寻找对应的入口点,跳转到 GOT 表中。如果这是第一次调用这个函数,程序会通过 GOT 表再次跳转回 PLT 表,运行地址解析程序来确定函数的确切地址,并用其覆盖掉 GOT 表的初始值,之后再执行函数调用。当再次调用这个函数时,程序仍然首先通过 PLT 表跳转到 GOT 表,此时 GOT 表已经存有获取函数的内存地址,所以会直接跳转到函数所在地址执行函数。
通过以上的介绍,那么实现修改函数的地方在于GOT表里的函数地址修改,让GOT执行的是我们需要的函数即可。既然这样,接下来需要做的工作是找到原函数的在GOT里的地址(GOT里函数的地址由PLT跳转,所以找PLT中函数的入口点)以及我们需要函数的地址,把我们需要的函数的地址替换到GOT
函数在动态链接库内的相对位置是固定的,在动态库打包生成时就已经确定。所以假如我们知道了某函数运行时地址(读取 GOT 表内容),也知道该函数和我们所需函数在动态链接库内的相对位置,就可以推算出函数的地址
最后在GOT中的替换修改,就需要用到上一个的ROP的方法实现
来源:
二、x64架构下的栈溢出
x64位下的十六个通用寄存器:

需要补充:在gcc下编译的才是把前六个参数依次放入rdi,rsi,rdx,rcx,r8,r9,而如果在VS编译环境下的只有前四个参数依次放入rcx,rdx,r8,r9
gcc编译环境:在通用寄存器中,函数执行前后必须保持原始的寄存器有3个:是rbx、rbp、rsp。rx寄存器中,最后4个必须保持原值:r12、r13、r14、r15。
保持原值的意义是为了让当前函数有可信任的寄存器,减小在函数调用过程中的保存&恢复操作。除了rbp、rsp用于特定用途外,其余5个寄存器可随意使用。
通用寄存器中,不必假设保存值可随意使用的寄存器有5个:是rax、rcx、rdx、rdi、rsi。其中rax用于第一个返回寄存器(当 然也可以用于其它用途),rdx用于第二个返回寄存器(在调用函数时也用于第三个参数寄存器)
x86和x64下的创建栈帧的过程基本一致,就不再赘述了。
二者简单区别在于被调函数的参数的存储位置
- x86
- 存储在主调函数的栈帧中,在函数返回地址的上方
- x64
- 函数的前六个整型或指针参数依次保存在RDI,RSI,RDX,RCX,R8,R9中,如果还有更多的参数的话才会保存在栈上
- 内存地址不能大于 0x00007FFFFFFFFFFF,6 个字节长度,否则会抛出异常
- 栈按照16字节对齐(就是说栈的大小是16的倍数)
来源于 CTF-wiki
栈溢出危险函数:
(1)输入
- gets 读取一行,忽略\x00(’\0’)
- scanf
- vscanf
- read
(2)输出
- sprintf
(3)字符串函数
- strcat 字符串拼接,遇到\x00(’\0’)停止
- strcpy 字符串复制,遇到\x00(’\0’)停止
- bcopy
补充(一些我不懂的知识点):
1、系统调用输入函数*read(int fd, void buf, size_t count)
size_t:表示无符号整数
ssize_t:表示有符号整数
(1)fd:将要读取数据的文件描述符;buf:所读取到的数据的内存缓冲;count:需要读取的数据量。
(2)fd为0时,表示为标准输入(键盘上获取输入),这时也是我们可以进行输入的时候;buf就是指一块存储空间,获取到的数据填入这里
(3)函数**write(int fd, void *buf, size_t count)**与之对应,是向buf缓存区写入一些数据,fd为1时表示为标准输出(显示在显示器上)
(4)fd=2时表示标准错误,这0,1,2是系统默认使用的,而3,4……等,可以由使用者自行决定
(5)成功返回读取的字节数,出错返回-1并设置errno,如果在调read之前已到达文件末尾,则这次read返回0
2、atoi() 功能是把字符串转换成整数(int类型的),还有个相同功能的**atol()**是把字符串转换成长整型数(long类型的)
3、python发送数据的固定格式为:$(python -c “print ‘\xe8\x05\xd9\x1d’ + ‘\x01’*16’ “)(这里pwnable.kr col题作为一个例子,强调这里不用\x00是因为会阻断)
随机数问题中的函数:rand() ,srand(),time()
1、rand()原型为:int rand(void) 。rand() 用来产生随机数,但是,rand()的内部实现是用线性同余法实现的,是伪随机数,由于周期较长,因此在一定范围内可以看成是随机的
(1)**rand()**会返回一个范围在0到RAND_MAX(32767)之间的伪随机数(整数)
(2)使用rand()函数产生0-99以内的随机整数:int number1 = rand() % 100; (如果要生成1-100,在后面加1即可)
(3)如果没有设置随机数种子,rand()函数在调用时,自动设计随机数种子为1(相当于srand(1)的情况)。随机种子相同,每次产生的随机数也会相同。
2、time():是C语言获取当前系统时间的函数,以秒作单位,代表当前时间自Unix标准时间戳(1970年1月1日0点0分0秒,GMT)经过了多少秒
(1)一般在随机数中,使用形式为time(0),获取正在变化的时间值,来配合srand()函数进行初始化函数发生器,生成不同的随机数
3、**srand()原型为:void srand (usigned int seed)**。用来设置rand()产生随机数时的随机数种子
(1)通常可以利用time(0)或getpid(0)的返回值作为seed
(2)使用srand()函数可以用来给rand()函数生成不一样的随机数种子
(3)使用rand()和srand()产生0-99以内的真正的随机整数: srand(time(0)); int number1 = rand() % 100;
注:用time(0)作为随机数种子时,两次程序运行的时间间隔要超过一秒,否则两次运行得到的随机数将一致
4、**memcpy()**函数原型为 **void *memcpy(void destin, void source, unsigned n) 功能为:从源source中拷贝n个字节到目标destin中,不会自动加上’\0’
5、**memset()原型为:void memset(void s, int ch, size_t n) 功能为将s中当前位置后面的n个字节用 ch 替换并返回 s
注:这里用ch做符号,是因为该函数只能取ch的低八位数,取值范围为0~255,跟字符的取值一样
6、memcmp()函数原型为**int memcmp(const void *str1, const void *str2, size_t n)**功能为比较内存区域buf1和buf2的前n个字节,str1>str2,返回正数;str1=str2返回0;str1<str2返回负数,比大小时,一旦能确认大小则停止比较,直接返回数值
7、rax eax ax ah al分别是:64位、低32位、低16位、ax的高8位、ax的低8位
8、**strchr()函数原型为:char *strchr(const char *str, int c)**功能为在str所指向的字符串中搜索第一次出现ASCII码值为c的字符的位置,若存在则返回该字符的地址,否则返回NULL
9、violatile关键字通常用来修饰多线程共享的全局变量和IO内存。告诉编译器,不要把此类变量优化到寄存器中,每次都要老老实实的从内存中读取,因为它们随时都可能变化。
10、函数返回值是通过寄存器进行返回的。编译器使用eax作为存储返回值的寄存器,被调函数在ret前设置eax,返回后,主调函数从eax获取到该值。
11、**mprotect()函数原型为int mprotect(const void *start, size_t len, int prot)**功能为mprotect()函数把自start开始的、长度为len的内存区的保护属性修改为prot指定的值(可读为4,可写为2,可执行为1)一般直接取7。
12、xxd命令可以查看文件的十六进制值,xxd 文件名 | tail可以打印十六进制值中的末尾数据。如果文件是被加上了upx压缩壳,可以输入upx -d 文件名 进行解压
13、**fflush(stdin)**是清空输入缓冲区的意思
14、malloc函数原型为为**void *malloc(unsigned int size)**;其作用是在内存的动态存储区中分配一个长度为size的连续空间。此函数的返回值是分配区域的起始地址,或者说,此函数是一个指针型函数,返回的指针指向该分配域的开头位置。
分配成功则返回指向被分配内存的指针(此存储区中的初始值不确定),否则返回空指针NULL。当动态内存不再使用时,应使用free()函数将内存块释放。
15、setvbuf原型 int setvbuf(FILE *stream, char *buf, int type, unsigned size) 用于设定文件流的缓冲区
type : 期望缓冲区的类型:
_IOFBF(满缓冲):当缓冲区为空时,从流读入数据。或者当缓冲区满时,向流写入数 据。
_IOLBF(行缓冲):每次从流中读入一行数据或向流中写入一行数据。
_IONBF(无缓冲):直接从流中读入数据或直接向流中写入数据,而没有缓冲区。
size : 缓冲区内字节的数量。
成功执行返回0,否则返回非零值
16、**/dev/random和/dev/urandomLinux**是系统中提供的随机伪设备。这两个设备的任务,是提供永不为空的随机字节数据流
用法:用open函数打开,然后从文件描述符中获取数据即可。
17、strcspn函数原型:**size_t strcspn(const char *s, const char * reject) **
功能:strcspn()从参数s 字符串的开头计算连续的字符,而这些字符都完全不在参数reject 所指的字符串中。简单地说, 若strcspn()返回的数值为n,则代表字符串s 开头连续有n 个字符都不含字符串reject 内的字符。
返回值为返回字符串s 开头连续不含字符串reject 内的字符数目。
18、回车 代码:CR ASCII码:/ r ,十六进制,0x0d,回车的作用只是移动光标至该行的起始位置;
换行 代码:LF ASCII码:/ n ,十六进制,0x0a,换行至下一行行首起始位置;
19、snprintf 函数原型**int snprintf(char str, size_t size, const char format, …)
功能:将可变个参数(…)按照format格式化成字符串,然后将其复制到str中。
(1) 如果格式化后的字符串长度 < size,则将此字符串全部复制到str中,并给其后添加一个字符串结束符(‘\0’);
(2) 如果格式化后的字符串长度 >= size,则只将其中的(size-1)个字符复制到str中,并给其后添加一个字符串结束符(‘\0’),返回值为欲写入的字符串长度。
1 | |
20、int execve(const char * filename,char * const argv[ ],char * const envp[ ])
execve()用来执行参数filename字符串所代表的文件路径,第二个参数是利用指针数组来传递给执行文件,并且需要以空指针(NULL)结束,最后一个参数则为传递给执行文件的新环境变量数组。
21、**getchar()**的返回值为输入字符的ASCII码值。又因为在字符串在内存里面都是以ASCII码值存储的,我们输入的payload都是字符串,换言之,进行循环的getchar就是另类的read
22、**extern char strdup(char s)
strdup()可以将字符串拷贝到新建的位置处,strdup()在内部调用了malloc()为变量分配内存,不需要使用返回的字符串时,需要用free()释放相应的内存空间,否则会造成内存泄漏。返回一个指针,指向为复制字符串分配的空间,如果分配空间失败,则返回NULL值
23、size_t getpagesize(void)
函数功能为:返回一分页的大小,单位为字节(byte)。此为系统的分页大小,不一定会和硬件分页大小相同。
返回值:内存分页大小。
24、**extern void memchr(const void buf, int ch, size_t count)
功能:从buf所指内存区域的前count个字节查找字符ch。
说明:当第一次遇到字符ch时停止查找。如果成功,返回指向字符ch的指针;否则返回NULL。
25、FILE *fopen(const char *filename, const char *mode)
- filename– 这是 C 字符串,包含了要打开的文件名称。
- mode– 这是 C 字符串,包含了文件访问模式。
功能:使用给定的模式mode打开filename所指向的文件;文件顺利打开后,指向该流的文件指针就会被返回。如果文件打开失败则返回 NULL,并把错误代码存在error中
26、size_t fread( void *buffer, size_t size, size_t count, FILE *stream )
- buffer–指向要输入的数组中首个对象的指针
- size– 每个对象的大小(单位是字节)
- count– 要读取的对象个数
- stream– 输入流
功能:从给定输入流stream读取最多count个对象到数组buffer中(相当于对每个对象调用size次fgetc),把buffer当作unsigned char数组并顺序保存结果。流的文件位置指示器前进读取的字节数。
27、**char strtok(char s[], const char delim)
功能:分解字符串为一组字符串。s为要分解的字符串,delim为分隔符字符(如果传入字符串,则传入的字符串中每个字符均为分割符)。首次调用时,s指向要分解的字符串,之后再次调用要把s设成NULL
返回值:从s开头开始的一个个被分割的串。当s中的字符查找到末尾时,返回NULL;如果查找不到delim中的字符时,返回当前strtok的字符串的指针。
28、*long int strtol(const char nptr,char **endptr,int base)
功能:strtol函数会将参数nptr字符串根据参数base来转换成长整型数,参数base范围从2至36
参数base代表采用的进制方式,如base值为10则采用10进制,若base值为16则采用16进制等。当base值为0时则是采用10进制做转换,但遇到如’0x’前置字符则会使用16进制做转换、遇到’0’前置字符而不是’0x’的时候会使用8进制做转换。
29、python2中的input()函数存在漏洞,会执行获得的输入,所以如果脚本存在引入os库输入os.system('/bin/sh')即可getshell,如没有引入os库,输入该内容__import__('os').system('/bin/sh') 也可getshell
30、
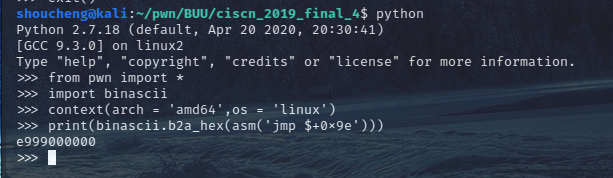 image-20211007195137781
image-20211007195137781
1 | |
可用该方法得到汇编的机器码
- 本文作者:ShouCheng
- 本文链接:http://shoucheng3.github.io/2020/11/15/2020-11-15-%E5%88%9D%E5%85%A5PWN/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!